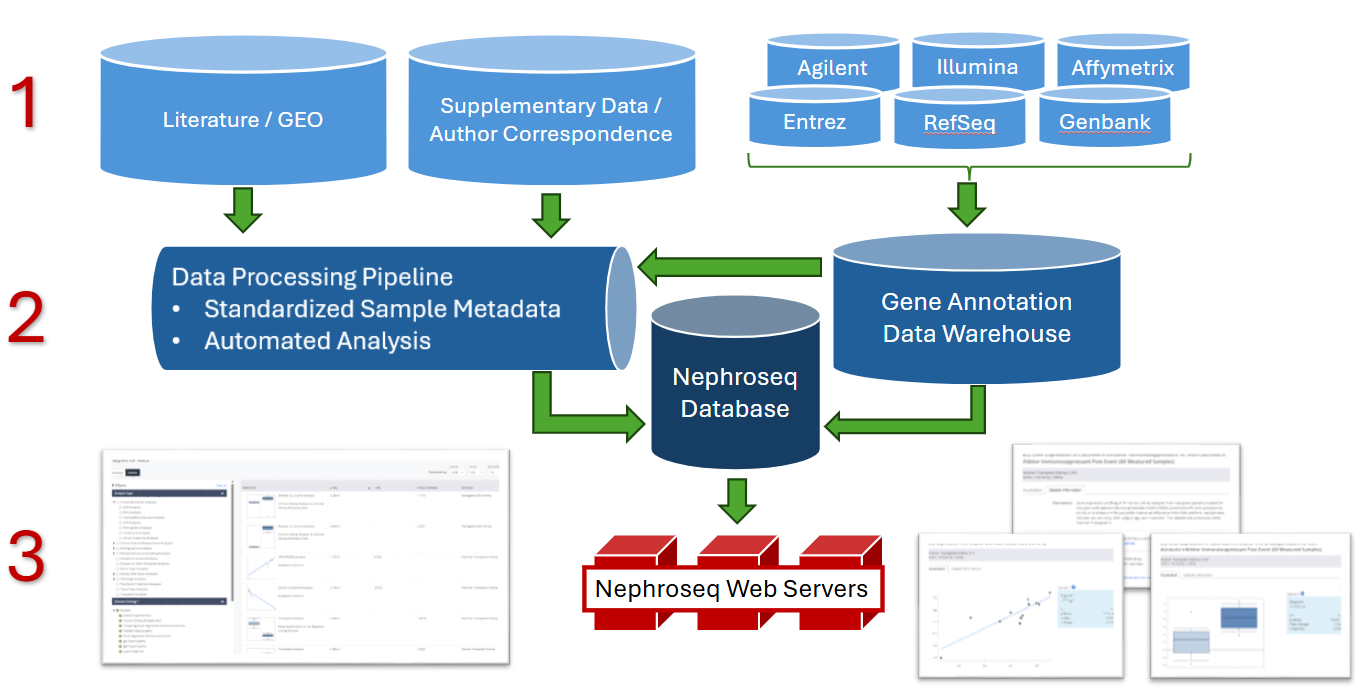
About the structure
The Nephroseq data structure can be broken into three layers:
1) Data input
This layer consists of the incoming gene expression data and gene annotation data. Candidate datasets are identified, prioritized, and pre-processed, including quality control steps.
2) Data processing and analysis
This layer consists of sample metadata standardization and automated statistical analysis. The metadata standardization utilizes an internally-developed ontology specific for chronic kidney disease. The automated statistical analysis component is implemented in Perl, Bash, and C. A series of scripts monitors the database for new data and sample parameters and automatically performs differential expression analysis and cluster analysis when needed.
3) Data visualization
The Nephroseq web servers query data from the Nephroseq database and display tabular and graphical representations of the data and analysis results.